
Effective feature flag management
The cost of neglecting feature flags: risks and best practices

Imagine a big healthy tree, that's your whole application. Every time you want to add something new, like a shiny red apple, you don't stick it right on the trunk. Instead, you grow a small branch for it. That way, if the apple turns out to be sour or sick, you can just trim the branch. The rest of the tree stays strong. In software development, this technique helps keep the application stable while testing new features. It's called feature flags and it's a smart way to manage changes in code without risking the entire system.
Feature flags have become an essential tool for enabling or disabling functionality without the need for application deployments. They're also commonly referred to as feature toggles. Under the hood, they’re a simple conditional that determines the code path that will be executed. When they’re not properly managed, they progressively acquire hidden complexity over time. In this article, we will explore how poor feature flag management leads to technical debt, the risks of embedding business logic, and best practices for managing them effectively.

Improving terminology
Choosing the right words matters. By reading the name, we should immediately understand its purpose. My recommendation is to add a prefix that explicitly states its intent. For instance, if it is intended to release a feature gradually, you could name it enable-dashboard-advanced.
We also need to obtain information about its lifecycle, specifically its end-of-life date. However, embedding the date in the name such as enable-dashboard-advanced-2025-07-01 is not ideal, as the date may change for various reasons, making it difficult to refactor.
What I suggest is adding this information directly in the third-party user interface. Most of the time, you can include a description linked to the feature flag. If there’s no place to store this information in the user interface, you can document it in the code. Here are a few key details related to the lifecycle that we need to capture:
Who maintain that feature flag ? Which team is owner of that?
When will need to clean the code and remove the feature flag?
What is the context? Is it related to any business goal?
Example
Feature: enable-dashboard-advanced
Owner: @team-a
Remove after: 2025-07-01
Context: Temporary flag to control rollout of dashboard advanced mode to improve user engagement
Now that we know what terminology to use, let's discuss how to identify and manage flags that are no longer needed.
Dead flags
A tipping point for technical debt is the presence of dead flags. Their initial goal has been fulfilled long ago, and now, no matter which parameter you use, it always returns the same result: either true or false. We could leave them aside, but sooner or later, you’ll work on a part of your application that will collide with that flag. This is when complexity increases, especially when you need to test the entire application. You’ll have to account for whether the feature flag is enabled or disabled, even if it always returns the same result. It could quickly become a nightmare if you have multiple flags colliding with each other.
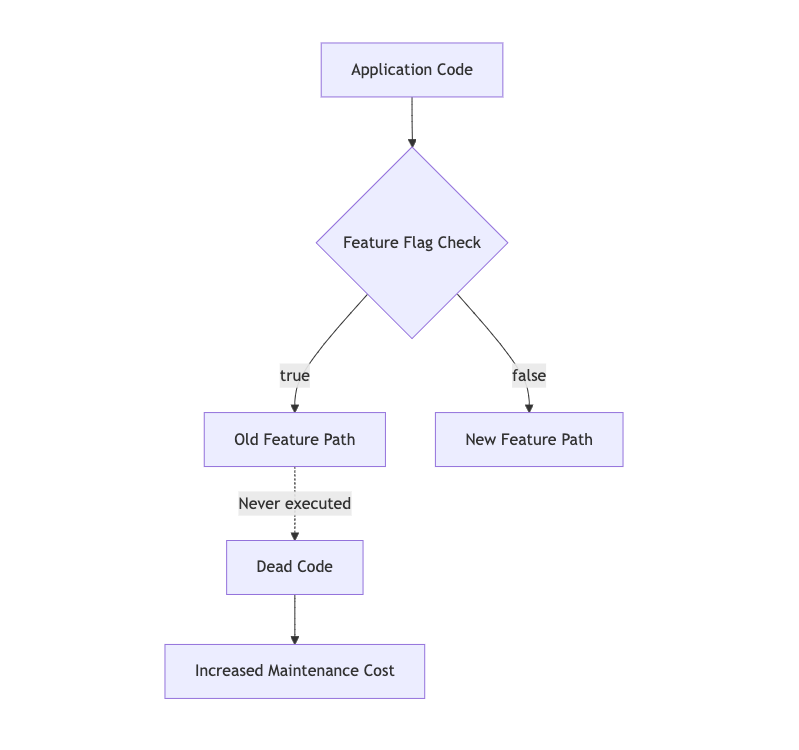
Is this flag still actively used?
Does it serve its intended purpose, or is it dead code meaning it's always enabled or disabled?
This is the easiest case to clean up because you can clearly see which path you want to keep and which part needs to be removed. My recommendation is to clean it up as soon as possible. During implementation, keep in mind that cleaning it up reduces code complexity. The future you will thank you for this cleanup.
Stale flags
Stale flags are those that have served their original purpose but are still active. Unlike dead flags, they don’t always return the same result, they’re often kept around in case they’re needed again under different conditions. This is a common scenario. For example, a feature might be enabled only in one region and due to legal or management decisions it is disabled elsewhere. The problem is, you might not know when or if it will be used again. That uncertainty is risky. Meanwhile, you’re likely to start building new features, and if these old flags start overlapping, it becomes hard to manage all the possible combinations. Just like dead flags, stale flags add complexity.
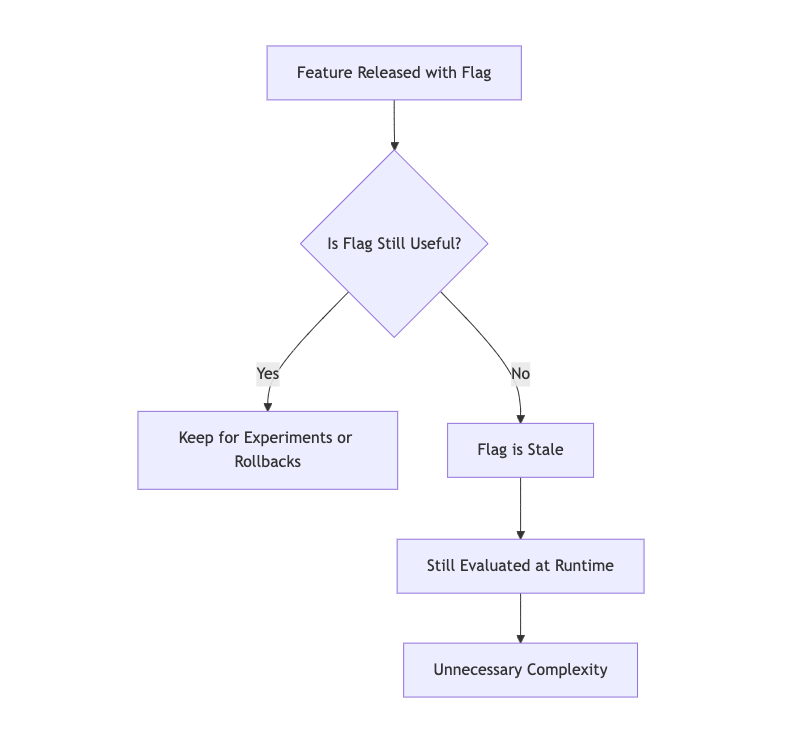
Which team is responsible for maintaining and reviewing this flag?
Is there a clear ownership to ensure it's cleaned up when no longer needed?
The recommendation here is to freeze the business logic. If the flag has already done its job (for example, enabling a feature in one region), you can remove the feature flag provider and hard-code the logic directly. This won’t necessarily make the code simpler, but it removes one layer of complexity. Without the feature flag provider, testing becomes easier, no need to fake feature flag provider. And if you need to enable the feature for another region later, you can just create a new feature flag for that specific case.
Hidden business logic
The hardest type of feature flag is the one that hides business logic. In this case, part of your application's logic is moved to an external service. This kind of trade-off give stakeholders autonomy, they can adjust that logic and monitor the impact in real-time. But there is a cost, the logic is no longer centralized and now depends on a third party provider. This introduce a point of failure and make it harder to catch issues during unit tests. It’s always possible to anticipate possible cases and simulate the logic externally, in practice, things rarely go as planned. If you give someone a tool, don't expect them to use it exactly as intended. New needs will emerge, and the logic will likely evolve in a ways you didn't foresee.
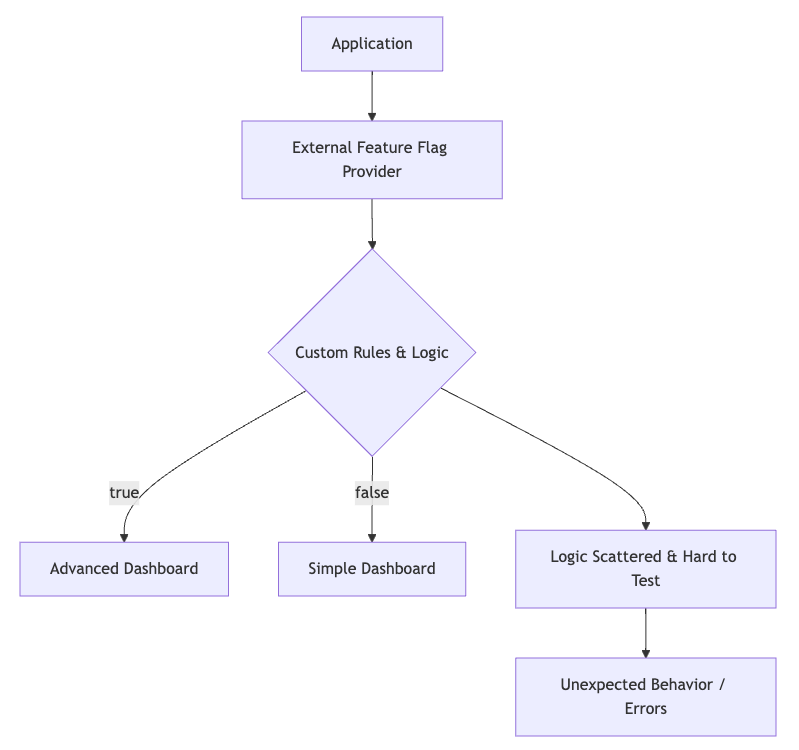
Imagine your application has a simple dashboard, and you want to introduce an advanced version but only for users with deep knowledge of your application. Both dashboard need to exist side by side on your application, and you've handed off the job of deciding which one to show to an external feature flag provider. Your team wants to experiment with different rules to find the right audience for each version of the dashboard. But this choice adds complexity to your code. At some point your feature flag might collide with others creating unexpected behavior.
My recommendation is to refactor the logic out of the flags and keep it inside your application. To keep things flexible, add a layer of abstraction, like an admin user interface or a JSON configurable file so it's still easy to update. Before deploying any changes, make sure to validate them. A good way to do this is to run behavior driven development using continuous integration which can catch issues early.
TL;DR
🌠 The key takeaway from this post is to stay mindful of why each feature flag exists. While flags are powerful tools for managing releases and experimentation, poor hygiene such as leaving them unmaintained, embedding business logic in them, or lacking clear ownership can quietly introduce technical debt.
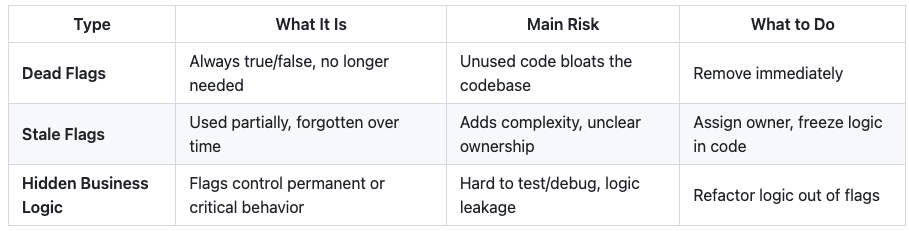
Common issues include dead flags bloating the codebase, stale flags creating ambiguity, and hidden logic behind flags where it doesn’t belong. These problems make the application harder to debug, maintain, and understand. To avoid them, use clear naming conventions, document each flag’s purpose and lifecycle, assign ownership, and regularly review and remove outdated flags. Be intentional: understand why a feature flag exists, track its usage, and adopt routines to review and clean it up when it's no longer needed.
Further Reading & Inspirations
💡 After publishing this article, a conversation with Kevin Marques sparked an idea:
What if a lint rule could flag expired feature flags?
So, I built eslint-plugin-feature-flags.
✅ It highlights outdated flags directly in your IDE and CI
✅ Encourages regular cleanup
✅ Lightweight and fits seamlessly into existing workflows
🔗 Check it out: https://github.com/arnaud-zg/eslint-plugin-feature-flags
I'd love your feedback!